Define the future of live with us
We believe innovative partnerships will shape the next generation of entertainment. Discover how our world-class solutions and local teams can work with you to maximize your box office potential.
Our solutions break records
With access to the best live entertainment tools in the industry, we’ll help you unlock your venue’s potential like never before.
EagleBank Arena Streamlines their Event Set Up

80%
Less Time Spent on Scaling
Our collaborative event creation tools helped EagleBank Arena cut its event publishing and setup time to less than 10 minutes.
NHL Seattle Surpassed Deposit Goal for Season Tickets

10K
Season Ticket Deposits Placed in 12 Minutes
Our tools empowered the Seattle Kraken to secure 33,000 season ticket deposits in just 24 hours.
Serving Up Digital Ticketing at the US Open
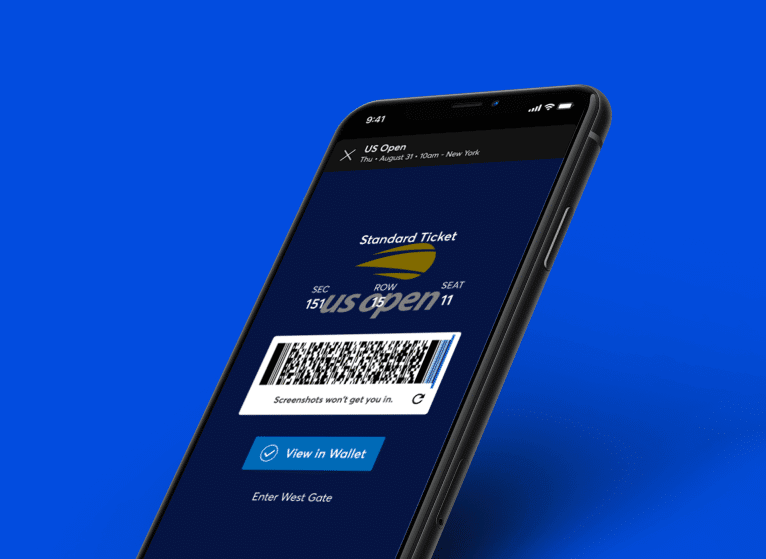
100K
New Names Added to Fan Database
The US Open saw incredible results, with 96% of fans using SafeTix to enter.
Optimizing Lead Generation with Our Marketing

6K
Leads Generated
Using Ticketmaster’s Marketing Solutions, The University of Kentucky achieved a 5% conversion rate, and significantly reduced their cost per lead.
TikTok & Ticketmaster Expand Global Partnership for Direct Ticket Sales
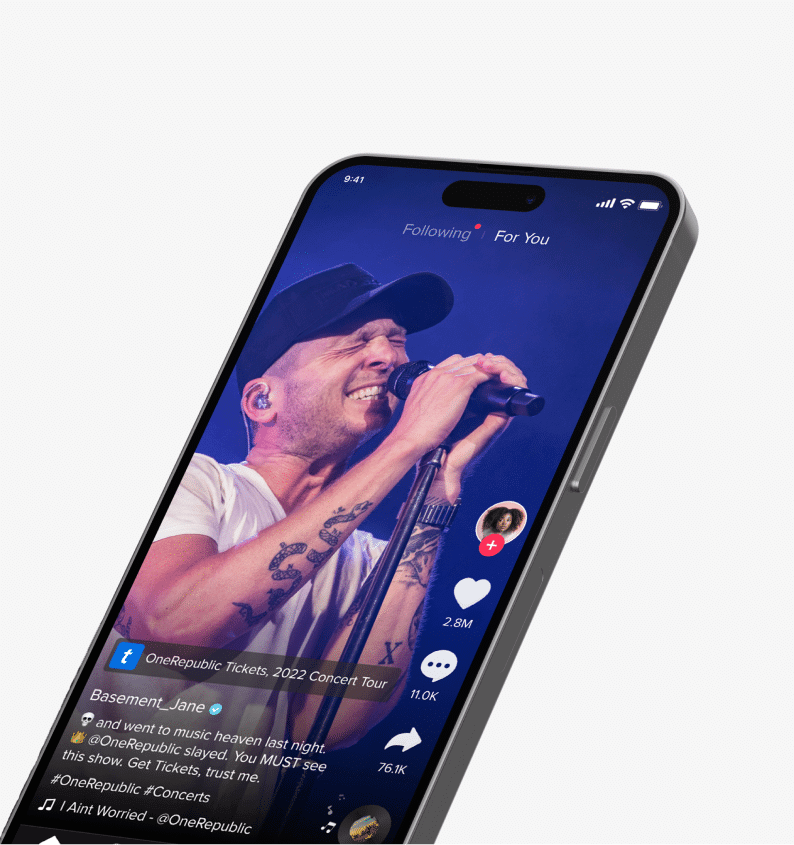
20+
Countries Utilizing In-App Ticket Links
TikTok and Ticketmaster join forces in 20+ countries, enabling artists to sell tickets directly on the app.
How Penn State’s Basketball Reseat Was a Slam Dunk

82%
Fans Required No Assistance During Seat Selection Process
Our tools gave fans an easy experience when it mattered most, reducing seat selection time for Penn State to under 12 minutes.
global clients, local partners
We work in-person, up close and personal, with stages and stadiums of all shapes and sizes all over the world. Here’s what our clients have to say about the difference our scalable platform makes for them.

“We’re always exploring innovation and technology and, candidly, we do a lot of that with our ticketing partner, Ticketmaster, who is always willing to do that right alongside us.”
Bobby Gallo
SVP for Club Business Development, NFL

“Ticketmaster offers an unmatched set of technology, tools and expertise which will serve to accelerate the growth of our fanbase. The sport is on the rise like never before and we look forward to taking the sport to new heights with our partner Ticketmaster.”
Gary Stevenson
MLS Deputy Commissioner, and President and Managing Director of MLS Business Ventures

“Ticketmaster’s customer service & revenue generating tools make it possible to do the things we care about — like expand our Education/Community Engagement programs, bring in creative programming and generally better pursue our vision of being The People’s Theatre.”
Josh La Belle
Executive Director, Seattle Theatre Group

“UniverSoul Circus has partnered with Ticketmaster for 30 years. The comprehensive services provided by Ticketmaster has helped grow our business from 14 shows annually to over 800. This was only achievable because Ticketmaster offers a unique cohesive experience that connects us, the business partner along with the customer, we both share.”
Cedric G. Walker
President/CEO, UniverSoul Circus
Results-driven insights
All of our best ideas start with you. We build solutions with your needs in mind to move the industry forward. Dive into our Insights to get a taste of what we’ve learned from working with you along the way.

Innovating Venue Entry at the Gate

The Future of Fan Engagement

From Presale to Showtime: Why WWE Partners With Ticketmaster for Professional Wrestling’s Biggest Events
FAQs
What does working with us look like? Every client relationship is different, but we’ve collected answers to common questions to help you understand what that means for you before you get on a sales call.
What can I expect in terms of client support and response time from Ticketmaster?
At Ticketmaster you don’t have to wait – every client has a dedicated Client Support Specialist and access to around-the-clock support through our Support Community, which even has its very own AI-powered Chat-bot! In addition, we provide an array of self-service tools that offer the flexibility you need to control all aspects of your business from event build to event day.
What specific tools does Ticketmaster offer to maximize marketing opportunities for my event?
Tools, automations and services are all a part of Ticketmaster’s robust marketing engine. Our marketing application within TM1 let’s you place pixels across your event pages, find the right audiences within your database, launch marketing campaigns across Ticketmaster’s on platform ad-network and more – with even more features to come in 2024.
What types of clients does Ticketmaster support? Can Ticketmaster cater to businesses like mine?
Ticketmaster and its subsidiaries have solutions for every event that needs a ticket – regardless of size and/or genre. Our clients range from small music clubs, to historical performing arts theaters to global sports leagues and everything in between.
Is your system PCI compliant and P2PE certified?
Yes. We take compliance very seriously.
What technologies does Ticketmaster use to support my ticketing needs?
Through powerful core ticketing platforms, flexible SDKs, APIs and integrations with partners, we’re able to meet the unique needs of all event organizers.
Can I manage events efficiently using Ticketmaster’s self-service tools?
Absolutely! Using TM1 Events, you can create and launch an event in less than 8 minutes, while collaborating with other key stakeholders directly within the TM1 app.
Does Ticketmaster only ticket concerts and sports?
Ticketmaster supports all genres of business, all around the world! Our scale ensures we have best practices from family to arts, sports to concerts, and beyond. Ensuring we have the knowledge and insight to help you tailor your ticketing plans to the right type of fan, to maximize your events opportunity.
let’s take the next step together
We are the global leader in live entertainment, and we’re doing more than ever to help power your business. Discover why thousands of clients trust us as their ticketing partner.
- Industry-Leading Tools
- Dedication to Innovation
- The First Place Fans Look for Tickets
- Largest Database of Ticket Buyers
- Best-In-Class Fan Experience
- Dedicated Account Team of Industry Experts
